Image Captioning in Vietnamese
Undergraduate Thesis. Built a Vietnamese dataset from MS-COCO and trained CNN+LSTM models.
Project Details
Role
Student Researcher
Team Size
1
Duration
Feb 2018 - Oct 2018
Overview
Fun Fact
This is my Undergraduate Thesis, my first experience with research paper writing.
The Challenge
Image captioning—automatically generating natural language descriptions for images—has achieved significant progress in English. However, for low-resource languages like Vietnamese, the lack of labeled datasets poses a major hurdle. This project aimed to bridge that gap by constructing a dataset and exploring diverse methodologies to adapt English-centric models to Vietnamese.
Dataset Construction
To create a benchmark for Vietnamese image captioning, I employed a semi-automated approach to translate a subset of the MS-COCO dataset.
- Source: 4,000 images from the MS-COCO training set.
- Volume: 20,000 image-caption pairs (5 captions per image).
- Process:
- Machine Translation: Used Google Translate for initial candidates.
- Human Translation: Manually refined translations to ensure cultural nuances and grammatical correctness were preserved, correcting errors where the machine translation conflicted with the visual content.
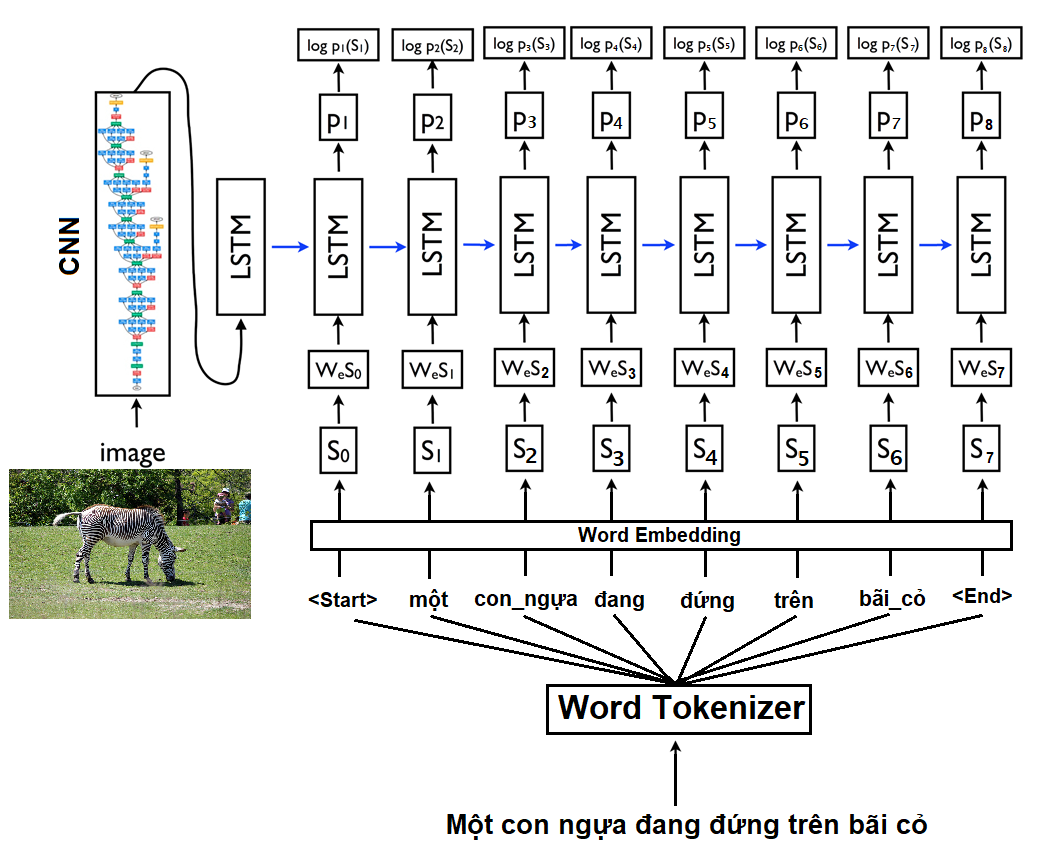
Methodology
The core architecture utilized the Show and Tell model (CNN + LSTM). I experimented with four distinct strategies to determine the most effective approach for Vietnamese:
- Translate-First: Generating English captions and translating them to Vietnamese (CIDEr: 0.827).
- Machine-Translated Training: Training directly on Google-translated captions (CIDEr: 0.935).
- Human-Translated Training: Training on manually quality-controlled captions (CIDEr: 1.095).
- Tokenized Training: Applying Vietnamese word segmentation (using RDRsegmenter) to handle the space-delimiter ambiguity in Vietnamese before training.
Results
The experiments demonstrated that data quality and language-specific preprocessing are crucial.
- Impact of Human Translation: Training on high-quality, human-translated data significantly outperformed machine-translated baselines.
- Impact of Tokenization: Vietnamese words often consist of multiple space-separated syllables. Treats them as single tokens (e.g., "trưởng thành" vs "trưởng", "thành") improved the CIDEr score to 1.148, the best result in the study.
| Method | BLEU-1 | BLEU-4 | CIDEr |
|---|---|---|---|
| English Baseline | 0.677 | 0.249 | 0.949 |
| English-to-VN (Translate) | 0.630 | 0.191 | 0.827 |
| Google-Translated Train | 0.639 | 0.251 | 0.935 |
| Human-Translated Train | 0.683 | 0.284 | 1.095 |
| Tokenized Human-Translated | 0.686 | 0.281 | 1.148 |
Conclusion
This thesis established a baseline for Vietnamese image captioning, showing that while transfer learning from English is viable, adapting to the specific linguistic characteristics of Vietnamese (like word segmentation) yield the best performance.
Key Achievements
- Built a Vietnamese Image Captioning dataset by translating 4,000 images and 20,000 captions from MS-COCO
- Investigated the impact of word segmentation on Vietnamese captioning
- Achieved 1.148 CIDEr score with Tokenized Human-Translated method