
Sanskrit to Vietnamese Translation
Benchmarking Modern LLMs on Ancient Buddhist Scripture Translation (Sanskrit/Pali to Vietnamese).
Project Details
Role
Researcher
Team Size
Individual
Duration
a weekend project in Jan 2026
Links
Overview
1. Research Motivation
This project aims to evaluate the capability of modern Large Language Models (LLMs) in translating ancient Buddhist scriptures (Sanskrit and Pali) into Vietnamese. The core research questions address:
- Can LLMs match the translation quality of renowned human scholars (e.g., Thich Nhat Hanh, Thich Minh Chau)?
- Which LLM currently performs best for this specific low-resource, domain-specific task?
- Is Sanskrit or Pali a better source language for translation quality into Vietnamese?
2. Technical Stack
The benchmark is built with a modular Python architecture using modern tooling:
- Language & Manager: Python 3.12+, managed by
uv. - LLM Interface:
litellmfor unified API access to various providers (Groq, Gemini, etc.). - Configuration:
hydra-corefor hierarchical configuration management. - Data Handling:
pandasfor CSV manipulation,pydanticfor data validation. - Caching:
diskcachefor persistent disk-based caching to handle API rate limits and resume interrupted runs. - Scoring:
sacrebleu(BLEU) andbert_score(Semantic similarity withtorch). - Observability:
langfusewithopentelemetry(API, SDK, OTLP exporter) for tracing and experiment tracking. - Reliability:
tenacityfor retry logic with exponential backoff. - Templating:
jinja2for prompt template rendering. - Data Crawling: Modular crawler design (
src/crawlers/) usingcloudscraperandBeautifulSoupfor robust data collection from Buddhist websites. - Prompt Versioning: Structured management (
src/system_prompts/) ensuring reproducibility and traceability of LLM behaviors. - Local Inference:
vllmfor serving local models (e.g. Qwen2.5) with OpenAI-compatible API. - Infrastructure Monitoring:
prometheusandgrafanafor tracking vLLM metrics (GPU usage, request latency).
3. Data Sources
The benchmark utilizes parallel datasets comparing ancient texts with human translations:
- Sanskrit → Vietnamese: based on the Heart Sutra (Bát Nhã Tâm Kinh),
sanskrit_vi_heart_sutra.csv. - Pali → Vietnamese: based on the Dhammapada (Kinh Pháp Cú),
pali_vi_dhammapada.csv. - Parallel Comparison: A dataset aligning Dhammapada (Pali) and Udanavarga (Sanskrit) verses,
dhammapada_udanavarga_parallel.csv.
Langfuse Datasets (Data Management)
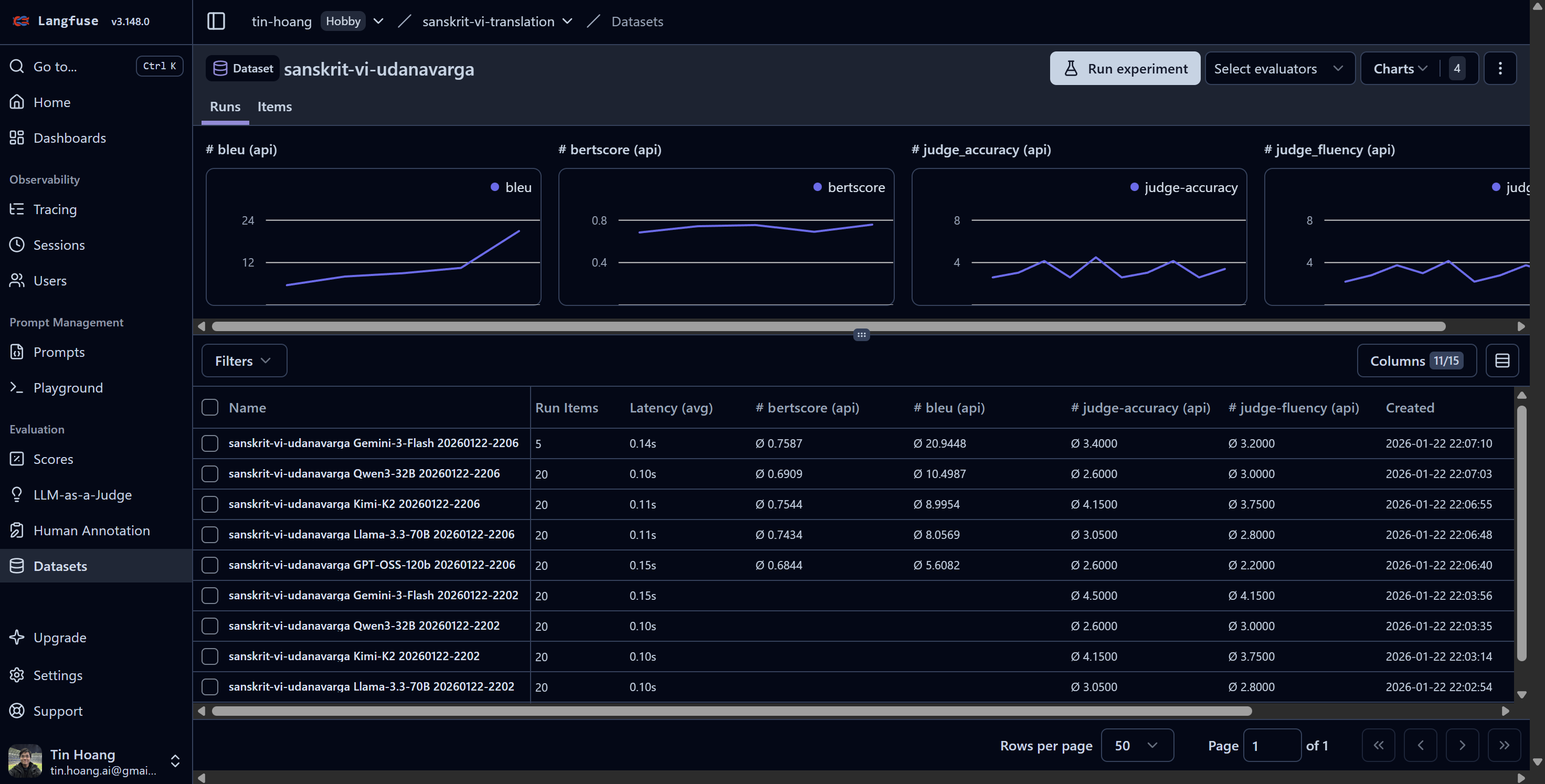
Langfuse Dataset Screenshot
The benchmark supports auto dataset uploading into Langfuse:
- Auto-Sync: When running with a local file, it automatically checks if the corresponding Langfuse dataset exists. If the local file has more items, it upserts them.
- Schema Enforcement: All datasets utilize Langfuse's Native Schema Enforcement to ensure data validity:
input: String (Source text)expected_output: Dictionary (Reference translations)
- Evaluation Scores Dashboard: scores are visualized in Langfuse dashboard grouped by model and dataset.
4. Evaluation Metrics
The project employs a multi-faceted evaluation strategy:
- BLEU Score: Measures lexical overlap with human references (
sacrebleu). - BERTScore: Measures semantic similarity using contextual embeddings (
bert-base-multilingual-casedimplied for 'vi'). - LLM-as-a-Judge: A qualitative assessment using
Gemini-3-Flash-Previewto score translations on a 1-5 scale for:
Accuracy*: Faithfulness to the meaning.
Fluency*: Naturalness of the Vietnamese text.
5. Models Benchmarked
The following models are currently evaluated:
- Llama-3.3-70b-versatile (via Groq)
- Llama-4-Maverick-17B (via Groq)
- GPT-OSS-120b (via Groq)
- Kimi-k2-instruct-0905 (MoonshotAI via Groq)
- Qwen3-32b (via Groq)
- Gemini-3-Flash-Preview (Google)
- GPT-5.2 (OpenAI)
- Grok-4-0709 & Grok-4.1-Fast-Reasoning (xAI)
- DeepSeek-V3.2-Chat & DeepSeek-V3.2-Reasoner (DeepSeek)
vLLM Monitoring (Prometheus + Grafana)
Support local LLM inference with vLLM and monitoring of vLLM performance, see the vLLM Monitoring Guide.
vLLM Dashboard on Grafana
6. Current Results Highlights
Sanskrit → Vietnamese (Heart Sutra | Bát Nhã Tâm Kinh)
Date: 2026-01-24
LLM Judge Model: gemini/gemini-3-flash-preview
Dataset: data/sanskritviheart_sutra.csv
| Dataset | Model | BLEU ↑ | BERTScore ↑ | LLM Judge Accuracy (1-5) ↑ | LLM Judge Fluency (1-5) ↑ | Time (s) ↓ |
|---|---|---|---|---|---|---|
| sanskrit-vi-heart-sutra | GPT-OSS-20B | 4.29 | 0.62 | 2.72 | 2.11 | 4.36 |
| sanskrit-vi-heart-sutra | GPT-OSS-120b | 8.52 | 0.71 | 3.00 | 2.61 | 9.32 |
| sanskrit-vi-heart-sutra | Llama-3.1-8b | 6.02 | 0.68 | 2.39 | 2.22 | 1.49 |
| sanskrit-vi-heart-sutra | Llama-3.3-70B | 15.82 | 0.72 | 4.00 | 3.61 | 2.89 |
| sanskrit-vi-heart-sutra | Llama-4-Maverick-17B | 21.72 | 0.75 | 4.67 | 4.22 | 4.54 |
| sanskrit-vi-heart-sutra | Kimi-K2 | 10.80 | 0.67 | 4.61 | 4.00 | 4.03 |
| sanskrit-vi-heart-sutra | Qwen3-32B | 11.50 | 0.75 | 3.83 | 3.33 | 4.76 |
| sanskrit-vi-heart-sutra | GPT-5.2 | 20.79 | 0.75 | 4.89 | 4.39 | 17.89 |
| sanskrit-vi-heart-sutra | Grok-4-0709 | 26.17 | 0.76 | 4.83 | 4.00 | 31.69 |
| sanskrit-vi-heart-sutra | Grok-4.1-Fast-Reasoning | 15.27 | 0.77 | 4.78 | 4.44 | 35.26 |
| sanskrit-vi-heart-sutra | DeepSeek-V3.2-Chat | 26.09 | 0.76 | 4.67 | 4.11 | 29.81 |
| sanskrit-vi-heart-sutra | DeepSeek-V3.2-Reasoner | 23.27 | 0.76 | 4.50 | 3.83 | 103.64 |
| sanskrit-vi-heart-sutra | Gemini-3-Flash | 33.73 | 0.76 | 4.94 | 4.56 | 11.11 |
Pali → Vietnamese (Dhammapada | Kinh Pháp Cú)
Date: 2026-01-24
LLM Judge Model: gemini/gemini-3-flash-preview
Dataset: data/palividhammapada.csv
| Dataset | Model | BLEU ↑ | BERTScore ↑ | LLM Judge Accuracy (1-5) ↑ | LLM Judge Fluency (1-5) ↑ | Time (s) ↓ |
|---|---|---|---|---|---|---|
| pali-vi-dhammapada | GPT-OSS-20B | 1.68 | 0.67 | 1.40 | 1.55 | 3.57 |
| pali-vi-dhammapada | GPT-OSS-120b | 5.96 | 0.70 | 2.45 | 1.95 | 10.84 |
| pali-vi-dhammapada | Llama-3.1-8b | 0.84 | 0.66 | 1.45 | 1.65 | 1.99 |
| pali-vi-dhammapada | Llama-3.3-70B | 9.27 | 0.77 | 3.05 | 2.75 | 5.13 |
| pali-vi-dhammapada | Llama-4-Maverick-17B | 15.75 | 0.78 | 4.20 | 3.90 | 3.06 |
| pali-vi-dhammapada | Kimi-K2 | 15.99 | 0.79 | 4.30 | 4.00 | 6.53 |
| pali-vi-dhammapada | Qwen3-32B | 13.58 | 0.77 | 3.25 | 3.05 | 4.71 |
| pali-vi-dhammapada | GPT-5.2 | 21.90 | 0.80 | 4.70 | 4.45 | 22.24 |
| pali-vi-dhammapada | Grok-4-0709 | 21.39 | 0.80 | 4.45 | 4.20 | 34.38 |
| pali-vi-dhammapada | Grok-4.1-Fast-Reasoning | 14.84 | 0.78 | 3.85 | 3.65 | 20.84 |
| pali-vi-dhammapada | DeepSeek-V3.2-Chat | 22.09 | 0.81 | 4.65 | 4.20 | 47.69 |
| pali-vi-dhammapada | DeepSeek-V3.2-Reasoner | 19.84 | 0.80 | 4.45 | 4.05 | 125.94 |
| pali-vi-dhammapada | Gemini-3-Flash | 32.67 | 0.83 | 4.65 | 4.45 | 8.47 |
Pali vs Sanskrit Comparison (Dhammapada - Udanavarga | Kinh Pháp Cú)
To analyze the comparative translation quality between Middle Indo-Aryan (Pali) and Old Indo-Aryan (Sanskrit) into Vietnamese, we constructed a multi-source parallel corpus based on the "Gāthā" (verse) literature of early Buddhism.
- Pali Source: The Dhammapada (Theravāda tradition), widely regarded as the most representative anthology of early Buddhist ethics.
- Sanskrit Source: The Udanavarga (Sarvāstivāda tradition), the Sanskrit textual cousin to the Dhammapada.
- Vietnamese References:
- Reference A (Liturgical): Translations by Thich Minh Chau (strictly adhering to the Pali Prime).
- Reference B (Modern/Natural): Contemporary prose translations focusing on intelligibility.
Date: 2026-01-24
Judge Model: gemini/gemini-3-flash-preview
Dataset: dhammapadaudanavargaparallel.csv (20 samples)
| Dataset | Model | BLEU ↑ | BERTScore ↑ | LLM Judge Accuracy (1-5) ↑ | LLM Judge Fluency (1-5) ↑ | Time (s) ↓ |
|---|---|---|---|---|---|---|
| pali-vi-dhammapada-18verses | GPT-OSS-20B | 1.41 | 0.67 | 1.72 | 2.17 | 6.97 |
| pali-vi-dhammapada-18verses | GPT-OSS-120b | 7.60 | 0.70 | 2.50 | 2.28 | 10.20 |
| pali-vi-dhammapada-18verses | Llama-3.1-8b | 1.59 | 0.71 | 2.00 | 2.33 | 1.89 |
| pali-vi-dhammapada-18verses | Llama-3.3-70B | 9.00 | 0.76 | 3.72 | 3.22 | 4.39 |
| pali-vi-dhammapada-18verses | Llama-4-Maverick-17B | 16.60 | 0.80 | 4.22 | 3.72 | 2.95 |
| pali-vi-dhammapada-18verses | Kimi-K2 | 11.61 | 0.72 | 2.88 | 2.94 | 5.42 |
| pali-vi-dhammapada-18verses | Qwen3-32B | 12.02 | 0.78 | 3.17 | 3.06 | 4.44 |
| pali-vi-dhammapada-18verses | GPT-5.2 | 19.49 | 0.80 | 4.67 | 4.44 | 21.71 |
| pali-vi-dhammapada-18verses | Grok-4-0709 | 20.52 | 0.79 | 4.33 | 3.78 | 33.42 |
| pali-vi-dhammapada-18verses | Grok-4.1-Fast-Reasoning | 13.35 | 0.78 | 4.06 | 3.56 | 11.16 |
| pali-vi-dhammapada-18verses | DeepSeek-V3.2-Chat | 27.39 | 0.81 | 4.56 | 4.50 | 42.27 |
| pali-vi-dhammapada-18verses | DeepSeek-V3.2-Reasoner | 18.16 | 0.80 | 4.00 | 3.72 | 112.90 |
| pali-vi-dhammapada-18verses | Gemini-3-Flash | 37.58 | 0.84 | 4.67 | 4.56 | 6.33 |
| sanskrit-vi-udanavarga-18verses | GPT-OSS-20B | 1.75 | 0.67 | 1.61 | 1.89 | 5.49 |
| sanskrit-vi-udanavarga-18verses | GPT-OSS-120b | 5.29 | 0.70 | 2.00 | 1.89 | 8.32 |
| sanskrit-vi-udanavarga-18verses | Llama-3.1-8b | 4.18 | 0.72 | 1.72 | 2.56 | 1.77 |
| sanskrit-vi-udanavarga-18verses | Llama-3.3-70B | 8.34 | 0.76 | 3.06 | 2.72 | 3.84 |
| sanskrit-vi-udanavarga-18verses | Llama-4-Maverick-17B | 13.24 | 0.78 | 3.61 | 3.00 | 2.55 |
| sanskrit-vi-udanavarga-18verses | Kimi-K2 | 8.05 | 0.76 | 4.06 | 3.28 | 4.94 |
| sanskrit-vi-udanavarga-18verses | Qwen3-32B | 13.76 | 0.77 | 3.00 | 2.50 | 5.39 |
| sanskrit-vi-udanavarga-18verses | GPT-5.2 | 17.61 | 0.80 | 4.61 | 4.28 | 22.07 |
| sanskrit-vi-udanavarga-18verses | Grok-4-0709 | 15.52 | 0.79 | 4.33 | 3.83 | 43.94 |
| sanskrit-vi-udanavarga-18verses | Grok-4.1-Fast-Reasoning | 10.89 | 0.76 | 3.78 | 3.56 | 17.88 |
| sanskrit-vi-udanavarga-18verses | DeepSeek-V3.2-Chat | 18.58 | 0.80 | 4.67 | 4.17 | 42.37 |
| sanskrit-vi-udanavarga-18verses | DeepSeek-V3.2-Reasoner | 13.17 | 0.80 | 3.89 | 3.61 | 114.35 |
| sanskrit-vi-udanavarga-18verses | Gemini-3-Flash | 35.26 | 0.83 | 4.50 | 4.33 | 9.65 |
Key Achievements
- Benchmarked over 12 state-of-the-art LLMs (including GPT-5.2, DeepSeek-V3, Grok-4, Gemini-3) on specialized Buddhist translation tasks.
- Demonstrated Gemini-3-Flash's superior performance, consistently outperforming other models across all metrics.
- Created custom parallel validation datasets aligning Pali (Dhammapada) and Sanskrit (Udanavarga) verses with Vietnamese translations.